Why bother?
Well, to be honest, I wouldn’t have bothered, except this happened accidentally. You see, in the process of moving VMs to my Proxmox cluster, I filled up my Ceph storage. That’s bad. Perfectly reasonable mistake too, I think. Proxmox’s web interface doesn’t show what you’d expect for Ceph storage. Instead of seeing the pool used/pool total, you get a gauge with the physical storage used/physical storage total. Depending on your Ceph settings, the physical storage and the pool storage could be vastly different numbers–as they are in my case.
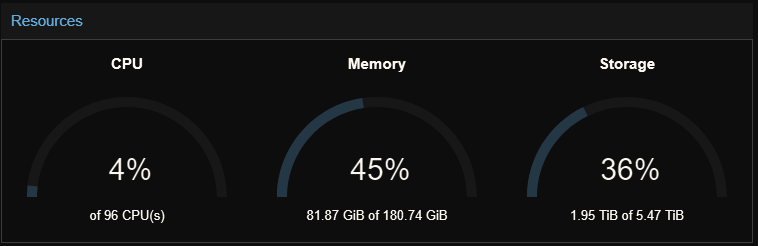
I look at that image and I think, “Cool, I’ve got 3.5 TB of free space. Time to move some VMs.” Wrong wrong wrong wrong wrong. Check this out:
proxmox# ceph df
...
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 431G 40.75 627G 112663
Oh, what? I thought I had 3.5 TB free. Nope, it’s actually 627 GB.
So here’s what happened: Late Saturday night, I wanted to move the last VM off of one of the VMware servers. It’s the biggest one because it’s also the most important–my Windows development desktop with remote access configured to the rest of my network. It’s called “controlcenter” for a reason. Anyway, it has a large virtual disk to accommodate downloads, builds, and whatever else I’m doing. In fact, this virtual disk is so large that I can’t qemu-img convert it on the Proxmox host, I’m going to have to use my NFS storage to host it and then migrate it to Ceph.
No problem, I figure. After all, everything has gone swimmingly up until this point. I transfer the VMDK to the NFS server, convert the VMDK to raw, and then have Proxmox migrate the disk from NFS to Ceph. It’s a large disk, so it’s going to take a few hours. I go to sleep.
I wake up to IT hell. Everything is offline. I try to pull up the Proxmox web interface–no dice. Hold on a second, my laptop doesn’t have a network address. That’s odd. “Oh yeah,” I remember, “I just migrated the DHCP/DNS server VM over to Proxmox.” …And this is a serious problem. You see, I’ve been pretty gung-ho about putting all of my systems on the DHCP server and having reservations for hosts that need “static” addresses. No manual configuration on the servers themselves, just a nice, clean config file…until that config file isn’t available. My Proxmox servers no longer have IP addresses on my network which means that I can’t get on Proxmox to see what’s going on with the DHCP/DNS VM. Brilliant setup, me.
I still have no idea why everything broke in the first place, but my first task is to get things back online and usable. Fortunately, I have a separate VLAN and subnet on my switch for the IPMI for the Proxmox cluster hosts. Hop on the dedicated IPMI laptop, IPMIView over, and I see that Proxmox doesn’t have a network address. OK, first things first, convert the Proxmox hosts back to static addresses. I modify their respective /etc/network/interfaces to give them the addresses that they were getting from DHCP reservations and attempt to restart networking with systemctl restart networking. That doesn’t work, they still don’t have addresses. OK, I’ll do it manually then: ifdown eth0 && ifup eth0. Now it’s complaining about not being able to tell the DHCP server it’s cancelling its reservation. Whatever, the static IP is assigned, things should be OK.
I give my laptop a static address on the main network and access the Proxmox web interface. Next step is to turn on the DHCP/DNS VM and get everything running. Weird, it’s still running. Open the console, everything looks fine. I’m able to log in and everything. This VM has a static address on the network (who ever heard of a DHCP server giving an address to itself), so the networking config looks normal. I go to check the syslog for DHCP entries to see why it’s not handing out addresses.
# less /var/log/<tab>
And then nothing. Literally just sits there. I can’t CTRL+C it. The VM has become unresponsive because I wanted to tab complete /var/log. That’s new and different. It finally dawns on me that this is not the average DHCP server outage.
Spoiler: It’s Ceph’s fault
If you can’t tab complete or list files, there’s a very good chance that your storage has fallen out. I’ve seen similar enough behavior with NFS-backed VMs on VMware that I had an idea of where to look. The obvious first step is to check the Ceph cluster health in Proxmox. It’s extremely unhappy. The health is in error state. The pool is full.
What?! I was only moving 1 TB and I had like 3.5 TB free, right? Yeah, not so much. That’s when I got a quick lesson in physical storage vs. pool storage. First order of business, deleting a few old VMs to free up some space. I use Proxmox’s web interface to remove the remnants of my ELK stack. That’s so two years ago anyway. After a brief period in which Ceph reorganizes some things, the cluster health is in a warning state for low space, but things are not outright broken. VMs (partially) come back to life in that I can start using their filesystems again.
Still, I’m impressed. The VMs just seemed paused, but were perfectly happy to resume–or so I thought.
Proxmox did not like my on-the-fly modifications to the network interface. I was getting what I could only describe as half-assed networking. Some hosts could ping some hosts on the same subnet, but not others. I resigned myself to rebooting the host nodes and letting the networking sort itself out.
One of the great things about the Proxmox cluster has been the ability to live-migrate VMs between nodes since they’re on shared storage. This means that the VMs can start and stop on a schedule independent of the hosts. Whenever Proxmox needs an update, I go through and migrate the hosts off of one node, update it, reboot it, rotate VMs off of another node, rinse and repeat. This process has been seamless for months now…until this incident.
Proxmox’s half-assed networking meant that despite a quorate cluster and the node I was using seeing all four nodes as in and everything happy, everything was not happy. Several of the VMs outright disappeared during the live migration with Proxmox reporting that it could no longer find their configurations. Uh oh, hope I have backups. (Of course I do.)
Logging into the nodes manually shows that /etc/pve is in an inconsistent state. It’s supposed to be synchronized between the nodes, but there has clearly been some divergence. At this point, I give up on keeping VMs up throughout the process–I just don’t want to lose anything. Time to reboot the nodes. But wait, Proxmox literally won’t reboot with this failed live migration VM.
proxmox1# echo 1 > /proc/sys/kernel/sysrq proxmox1# echo b > /proc/sysrq-trigger
This is a reboot by force. It’s bad for everything. Note that this same functionality can be accessed through magic sysrq keys if your sysctl is set to allow it (or you echo 1 to /proc/sys/kernel/sysrq). I could’ve done the same thing through the special laptop with IPMI access, but since I was already logged into the node, this seemed faster.
After a reboot of the nodes, the networking issues are resolved. Proxmox is happier, I’ve got my backups ready in case the VM configs were somehow lost, and things are back on track. Proxmox actually (mostly) resolved its state issues and I didn’t have to restore anything from backup. The only problem remaining was that the VM that had failed live migration was locked and wouldn’t start.
# Unlock the VM with ID 100 proxmox1# qm unlock 100
And problem solved. Finally, everything is back to normal.
Lessons learned
- Don’t fill up your Ceph pool. Just don’t. It’s bad.
- This really underscores my need to get some monitoring in place. I’m sure there are some easy ways to monitor
ceph dfto keep track of pool size remaining.
- This really underscores my need to get some monitoring in place. I’m sure there are some easy ways to monitor
- Highly-available DHCP infrastructure
- Especially if, like me, you rely on DHCP for almost every host on your network. And highly-available means on different infrastructure so that something like a storage failure *cough* Ceph *cough* doesn’t bring down multiple DHCP servers.
- Backups. Have them.
- Storage is cheap. Your time is expensive. Save yourself the headache of rebuilding everything if the worst does happen.
- Ceph is pretty resilient.
- If the DHCP server hadn’t destroyed networking for everything, I think once I freed up the space in the Ceph cluster, everything would’ve resumed without issue. Generally speaking, I’ve been pretty happy with the Ceph backend for Proxmox and plan to add another Ceph cluster to my network at some point.